ユーザに検索機能を提供するシステムの開発を行わせていただいたのですが、このようなシステムは読み込みでDBに負荷がかかり、そこがボトルネックになりやすいです。50~100万件のレコードの中からユーザが求めているデータを取り出すという処理でしたが、検索条件が毎回ユニークであるためキャッシュがヒットしにくいという特徴もありました。そこで、Rails + RDSのリードレプリカを利用してDB負荷分散を行うことにしました。AWSとRailsで比較的簡単に実現できますのでご紹介いたします。
サーバ構成の概要
ざっくりと次の図の様なサーバ構成としました。
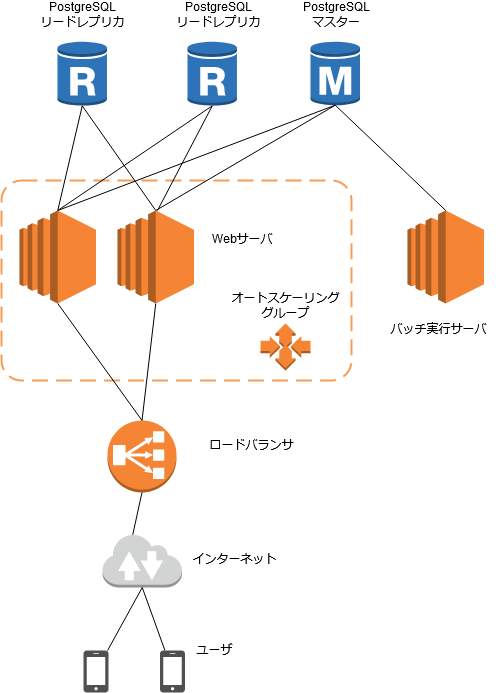
負荷分散構成で着目するのは次の3つです。
・DBサーバ:3台(マスター1台、スレーブ2台)
・Webサーバ: 2台(オートスケーリングで増える)
・バッチ実行サーバ:1台
ユーザからのアクセスが少ない早朝にバッチサーバがデータ登録を行い、Webサーバは検索機能を提供するだけとなっています。Master DBをバッチ処理だけで利用すると稼働が勿体無いのでMaster DBもWebサーバからreadを受け付けるように構築しました。
RDSのリードレプリカを利用
RDSを利用しているとMaster、SlaveのDBを構築するのはとても簡単です。ブラウザからAWSコンソールにログインして、RDSのページでMasterにしたいDBを選択し、アクションから「リードレプリカの作成」を選択して完了です。
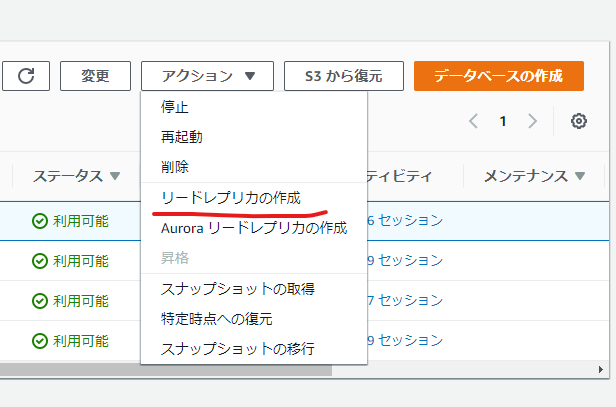
作成されるSlave DBはMasterに追加したデータが1秒以内には反映されるようです。(実際はどの程度の速度を保証しているかは確認していませんがかなり早い印象でした)。後はMaster DBに対してデータを追加・更新していけば全てのSlave DBに反映されます。
今回はPostgreSQLを使ったのですがリードレプリカは5台が上限となります。Auroraを利用すれば最大15台のリードレプリカが利用できるというのは魅力的でしたが、PostgreSQLのSQLで出ていた速度がAuroraにした時に出るかテストする時間がもったいなかったのでAuroraは見送りました。また、Auroraの方がwriteのパフォーマンスは良いという記事はあるのですが、readのパフォーマンスに関する記事があまり見当たらなかったことも少し気にかかりました。
Webサーバとバッチ実行サーバはgem replidogを利用
Webサーバとバッチ実行サーバはRailsを採用したのですが、DBの負荷分散ではラウンドロビンする仕組みが必要になります。つまり、DBからデータを読み出す時に、複数のSlave DBを順番に利用する仕組みです。
DBの負荷分散で利用できるgemとしては、octopus や switch_point といったものが有名らしいのですが、今回はシンプルな機能だけで良かったので replidogというgemを利用しました。
replidog: https://github.com/jemiam/replidog
このgemの良いところは、writeの時は自動でMaster DBを利用し、readの時は自動でSlave DBをラウンドロビンで参照します。さらに、明示的にMasterからreadを行うことも可能です。今回欲しかった機能にぴったりでした。
config/database.yml の一部ですが、次のようにmasterのhost、slaveのhostを定義するだけでOKです。
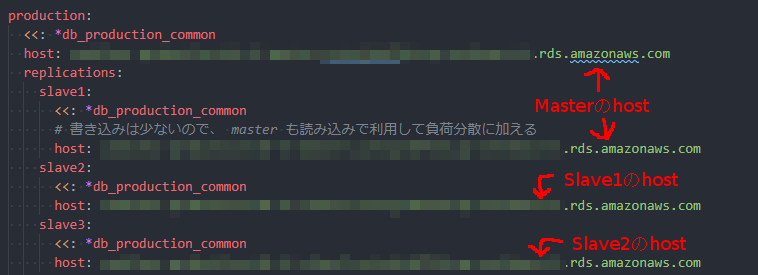
費用削減のため、MasterもSlaveの設定に加えて合計3台からreadする設定です。replidogを使うとmaster、slaveが簡単に設定できます。
これでも負荷が上がってDBを追加したい場合は、AWSでリードレプリカを追加し、database.ymlのslaveの項目にhostを追加、という手順で対応することになります。
まとめ
RDSとRailsでDBの負荷分散が簡単に実現できることをご紹介いたしました。しかし、DBが1台で足りるならその方が運用面でもコスト面でも有利なので、まずはSQLのチューニングから取り組みましょう。